PROCESS DOCUMENT
Motivation
- Why did you decide to take part in the AI Song Contest?
- I participated in last year’s contest and since then, I’ve become even more obsessed with trying new approaches of creating art and music with AI. For this year’s contest, I wanted to challenge myself to learn how to train my own datasets and play with parameters of existing resources. I’ve found experimenting with different machine learning models to be inspiring due to the nature of the unpredictability of what I get. After meeting Ramon unexpectedly during the lockdown and inspired by his amazing voice, I decided to venture into new experiments with our voices. Since my first experiments with CJ Carr over the last couple years, I’ve become very curious about combining unique datasets to see what kind of new sounds I can create. We allowed the music production to be led by the strange glitches and sonic textures that came out of these models. Lyrically, we were inspired by being able to plant and grow multiple seeds simultaneously to train and give birth to all these audio experiments. With creativity, there is always a constant push and pull between freedom and control. We allowed the natural tension of this ebb and flow with a lot of patient listening digging for the gold nuggets of new and strange sounds we’ve never heard before.
Workflow
- How did you curate and evaluate the training data (if any), algorithms, and AI outputs?
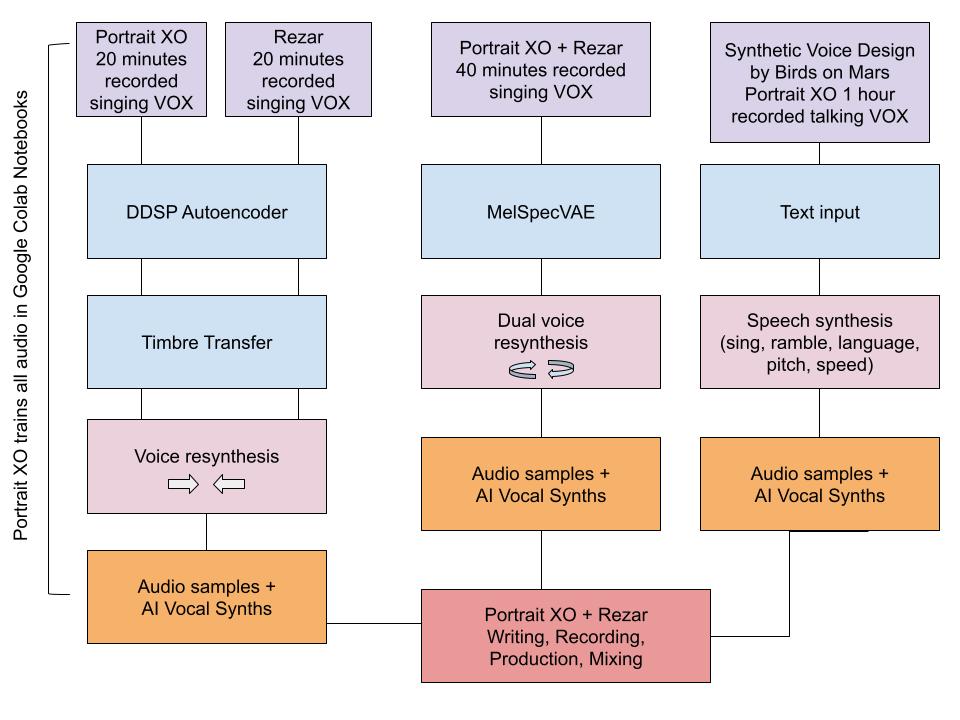
- Birds on Mars - custom synthetic voice design web-based tool (https://www.krach.ai/). After Birds on Mars trained 1 hour of Portrait XO’s talking voice and provided 5 models to play with (10-50 hours of training), we input words for text to speech audio for both narration and sound design. Krach’s web-based tool that allows altering the synthetic voice to alter the output with the following parameters: pitch, speed, new language, and sing.
- Recorded 20 minutes of singing (both individual recordings of Portrait XO and Ramon)
- Trained each set on Google Colab DDSP autoencoder https://colab.research.google.com/github/magenta/ddsp/blob/master/ddsp/colab/demos/train_autoencoder.ipynb
- Trained on Timbre transfer to upload small batches of audio recordings to resynthesis our voices from one to the other (Portrait XO singing directly into Colab of dataset trained on Ramon’s voice, and vice versa), and also recorded directly into Colab to produce a batch of AI generated samples to produce new music. https://colab.research.google.com/github/magenta/ddsp/blob/master/ddsp/colab/demos/timbre_transfer.ipynb
- Trained on Moises Horta Valenzuela’s MelSpecVAE both our vocals as 1 data set (40 hours of vocals) for one shot samples from latent space and interpolation through 2 different points in the latent space and synthesize the 'in between' sounds. Synthesize arbitrarily long audio samples by generating seeds and sample from the latent space. Noise types for generating Z-vectors are uniform, Perlin and fractal. https://github.com/moiseshorta/MelSpecVAE
- How did you combine different approaches, and the various musical components together?
- Human-machine collaboration feels best when co-creation happens holistically between human and machine. The human is the driver of translating experiences into cohesive ways for us to understand life. That’s what machines cannot do. Machines can be fun, unpredictable, and evoke emotions, but it can never tell the subjective story of a human experience. The AI generated audio we used ended up enhancing our musical skills of composing, producing and writing. It felt like an equal collaboration between human and machine.
- How are all of these influences reflected in the final result?
- Our track showcases the strange glitches and textures of these audio outputs. While MelGAN provided a lot of chirping and heavy crunchy sounds indicating the sound of a ‘machine thinking’, DDSP/Timbre Transfer and Birds on Mars models both shared more of a grainy/soft distortion in all the outputs. The lyrics are a direct reflection of how we felt about the process of a lot of patience, restarting notebooks that would sometimes get glitchy, and the rewarding feeling of finally finding flow when we sift through countless audio samples to piece together a palette of sounds we liked. We looked for audio that had interesting textures for percussive elements, turned some into sampled instruments, and others we used as inspiration for melodies and storytelling.
Creative use of AI tools for musicality
- Why and how did you choose to use AI tools in achieving your musical and creative goals?
- After working with CJ Carr on co-creating with AI generated audio in last year’s competition, I wanted to continue exploring how else can machine generated audio be inspiring from feeding original vocals as datasets. The human voice is the most emotional, dynamic, interesting, and evolving instrument we can ever have and use. Allowing the songwriting and production to support the machine generated audio was the feedback loop that became an inspiring way to co-create this glitchy, strange, and curious palette of sounds. Purely from a sound design perspective, there are so many micro possibilities of the types of sounds we can get because the type of data we feed can be so wide, not just sound. And this is the kind of possibility that can only be created with AI. The random nature of AI is what becomes an instant idea generator with flows of spark for new ideas from a constant state of being surprised. When we use our own original material as the raw data we input, it gives us a chance to become even more intimate with our work as we hear ourselves back in new unexpected ways. Thanks to CJ Carr and Moisés Horta Valenzuela, I was taught how to use Google Colab notebooks as a great starting point of learning how to train my own datasets.
- In what way did the use of AI tools support or hinder you in conveying the aesthetics, emotion, the story and the main message of your song?
- It proved to be a huge support for serving as a guide of the aesthetic for the production. Because of the constant surprising new sounds we got to play with, it gave us a new way of working that broke us free from traditional approaches to songwriting. Instead, it became like a game of creating a collage of sounds we felt fit well together. The melodies and lyrics ended up as our emotions and thoughts reflecting on the process. The only thing that was hindering was the data processing time, the glitchy colab notebooks that didn’t always work, and sifting through huge batches of audio that became repetitive and unusable. But the samples that made it into this track really helped shape and define the overall sound of this production we’re happy about.
- What surprised you about the AI tools output or interfaces? What abilities did the AI tool of your choice enable? Did you have to make tradeoffs based on tool limitations?
- The weird thing with Google Colab DDSP autoencoder was the sample rates changing unpredictably. For some reason, when the original audio input length was different to later audio inputs, it wouldn’t set the new audio length as the new length for the output, but kept the previous uploaded file length. This meant we got even stranger outputs with sample rates changing constantly (unless the audio in was always consistently the same exact length of time). When we trained both our voices in MelSpecVAE, we got 1 specific one shot sample that was a ‘goosebump’ moment. It sandwiched both our vocals and created a strange harmony with a weird effect that we loved.
- Did AI have an impact on the creative process? Would you have separated the elements of a song (melody, lyric, rhythm, etc) differently or approached them in a different order/direction if you were writing without AI?
- Yes. We ended up breaking free from a typical song structure of full verses, choruses, middle / outro sections. We became infatuated with showing off the new exciting sounds we discovered. Although there are real live vocals that were sung on this track, we were less worried about writing a full traditional song and more interested in putting together a collection of sounds that we felt sounded great. Taking inspiration from the short bursts of audio we could use for sampling, we took a similar approach to melodies and lyrics keeping them just as sparse. We kept all the instrumentation around the AI generated audio minimal to highlight these sounds and a sporadic poetic approach to lyrics and melodies.
Collaboration
- What was the most interesting to you in your collaboration process? What was the most challenging?
- Two artists unexpectedly meeting during the pandemic in Berlin’s lockdown restrictions has become a real rarity. And meeting another artist that syncs with similar stylistic interests with an amazing voice was an unexpected coincidence. Training AI models with both of our voices and getting interesting outputs. The most weird/interesting thing that happened was breaking Google Colab DDSP autoencoder notebook that kept changing audio output sample rates creating a new voice that sounded like Chewbacca. Trying new approaches to try and merge our voices together was really fun to see what kind of textures we'd get.
- In what ways did using AI in the songwriting process make your (remote) collaboration better? In what ways more challenging?
- It was always interesting to hear unpredictable results, that’s always the fun part. The challenging part was when we’d hear an audio sample that sounded great and wished it went on longer. And the small percentage of usable AI generated output. We needed to train quite a lot of data in bursts of time to sift through a lot of noise.
- How would you describe the role AI played as a "collaborator"?
- Exciting once you get through the patience game. It provides a constant spark creator, once you get your set of audio to play with, it can really help with breaking free from any form or structure to create your own, and the constant state of surprise is the best anecdote for writer’s block.
Diversity and ethical considerations
- How did you approach forming a diverse team and helping each team member contribute their best in the process?
- Ramon has an amazing voice with a great melodic and lyrical style. For the creation of this song, Portrait XO focused more on the curation of data to feed into models, trained the models with various different parameter changes, and sound hunted sifting through all the noise of the AI generated audio to download sounds that were interesting enough to use. Setting the tone with a new palette of sounds to start with, Ramon took lead in creating melodies, and together we fine tuned a short set of lyrics to translate our emotions with simple and soulful production. The lyrics became an organic and mutually agreed way of expressing how we felt about this production.
- Throughout the process, how did your team discuss the ethical issues that arise around data, models, musical output, creative agency and ownership?
- We’ve only had 1 session together to create this song so we haven’t had long enough time to venture too deeply into other topics around AI.
My first AI text to image music video

AI generated samples + AI vocal synth used in track